Chapter 10
Perception as construction of the world
Without any perceptual abilities, an agent can hardly do anything intelligent in the real world. Neural networks
already give a rudimentary system for perception: for an input image, they can try to tell what it depicts. But it
turns out that perception is an extremely difficult problem. In this chapter, I explain the main difficulties
involved in perception, and how they can be, to some very limited extent, solved by modern AI. However, I
argue that the very problem of perception is extremely difficult, and even our brains do not solve it very well.
Here, I consider in detail visual perception, but the theory largely holds for other kinds of perception, such as
auditory perception.
What is crucial for the main theme of this book is to understand the implications of the extreme difficulty of
perception. It means our perceptions are quite uncertain, or unreliable, and much more so than we tend to
realize. We fill in the gaps in the incoming information by using various assumptions, or prior information, about
the world. Therefore, one aspect of such uncertainty is subjectivity: we fill in the gaps using our own
assumptions, and my assumptions may be different from yours. Perception is essentially a construction, a result
of unreliable and somewhat arbitrary computations; it is not an objective and perfect recovery of some
underlying truth.
These fundamental problems in perception feed into the difficulty of making correct inferences about the
world: they make any categorization uncertain, they reduce the possibility of predicting the world, and
consequently reduce any control the agent has. This increases various errors such as reward prediction errors,
and thus suffering. More specifically, computation of reward loss is dependent on the prediction of reward as well
as the perception of obtained reward, which are both subject to the limitations of perception, and thus it can go
wrong.
Vision only seems to be effortless and certain
It may be suprising to many people to see how difficult computer vision actually is, and what an incredible feat
the visual system of our brain is accomplishing, literally, every second. It all seems to happen so effortlessly and
automatically. However, our capacity for vision is effortless only in the sense that it does not require much
conscious effort, and it is automatic only in the sense that it does not usually need any conscious decisions or
thinking. You turn your gaze towards a cat, and immediately, without any conscious effort, you recognize it as a
cat. This is a typical, even extreme case of dual systems processing: most of the computations happen in
neural networks, not at the level of symbolic, conscious thinking. Since we have little access to
the processing in the neural networks, we cannot understand how complicated their computations
are.
In the early days of AI in the 1970s, computer scientists thought programming such “computer vision” must
be easy. However, anybody either studying the human visual system or trying to build a computer vision system
is quickly convinced of the near-miraculous complexity of the information-processing needed for vision, and
performed by our brain almost all the time. Knowing that history, it is not surprising that while
computers can beat humans in chess or arithmetics, they are nowhere near human performance in visual
processing.
Too much data
A major difficulty in vision is the huge amount of data received by the system. The immensity of the
data is perhaps obvious to anybody who has waited for video data to download over a mediocre
internet connection. In fact, the vast majority of internet traffic takes the form of video data. Text
data is completely negligible in terms of file size: a large book is hardly equal to a second of video
data.
Likewise, humans and other mammals receive a huge, continuous stream of data from the
environment through their eyes. The human retina contains something like one hundred million
photoreceptors, which are cells that convert incoming light into neural signals. The manner in which the
data is stored and transmitted may be very different from computers, but still the fundamental
problem of receiving an immense amount of data is there, as well as the requirement of a huge
amount of information-processing capacity. In fact, the visual areas constitute something like half
of the human cerebral cortex—the part of the brain where most sophisticated processing takes
place.
Yet, information is missing
Having such huge amounts of data is both a blessing and a curse. A curse obviously in the sense that you
need immense computing power to handle such a data deluge; a blessing in the sense that such
huge amounts of data may contain a lot of useful information. Yet, paradoxically, the information
contained in the input to a camera or the retina is almost always lacking in various important
ways.
One of the most fundamental problems in vision is that what each eye gives us is a two-dimensional
projection of the world, just like an ordinary photograph. A photograph is nothing like a 3D hologram: most of
the information on the 3D structure of the objects is missing. (Having two eyes gives some hints of the 3D
structure, i.e. which objects are close to you and which are far-away, but this only slightly remedies the
problem.)
Suppose you see a black cat. Now, the actual 2D projection will be very different when you can see the
cat from different viewpoints: from the front, from one side, from the other side, from above, and
so on. That is, the pixels which are black are not at all the same in the different cases; the pixel
values that would be input to a neural network will vary widely when the cat is seen from different
viewpoints. Thus, the neural network will have to somehow understand that very different pixel values
correspond to the same object. To illustrate this problem of 3D to 2D conversion, consider what even
a simple cube can look like in different projections. Some possibilities are shown in Figure 10.1.
Its 2D projection can look like a rectangle (possibly a square), like a diamond, and many other
things.
And this is just one kind of information lacking. More fundamentally, the problem is that any object can
undergo many different kinds of transformations. Consider a cat again: it can take many different shapes by
moving its limbs; sometimes its legs are wide apart, sometimes close to each other. Sometimes it stretches its
whole body, sometimes it puffs up. If you think about the 2D image created, it will again be quite different in
these different cases. As another example, the lighting conditions can be very different. Imagine that light comes
from above, or from behind the cat: Again the cat looks very different, and even more so in a 2D
projection.
Those were some of the problems in recognizing a single cat. To make things even more complicated,
different cats look very different. Some are black, some are white, so the pixel values are even more
fundamentally different. Yet, you somehow are able to see that they are all cats.
Such ambiguity, or incompleteness of visual information in a camera or the retina is the reason why vision is called an
inverse problem.
As a very simple illustration of an inverse problem, consider there are two numbers which we denote by
the variables x and y. You want to know both these numbers, but the trick is you only are given
their sum, x + y. How could you possibly find out both of those original numbers—how can you
“invert” the equation? Suppose you are told the sum of two numbers is equal to 10. There are many
possibilities what the actual x and y may be like, for example, x = 5 and y = 5, or x = 7 and
y = 3 etc. Vision is a lot like this. What you observe are the pixel values in, say, a photograph.
But there are a lot of factors that determine what the pixel values are like: the identity of the
object in the photograph, the location of the object, the lighting conditions, the background, to
name just a few. It is next to impossible to figure out what there is in the image without some
tricks.
Actually, the fact that perception is based on incomplete information is in some sense quite blatant. Just
think about the fact that you cannot see through solid surfaces. Suppose you look at a wall in front of
you: you cannot see what is on the other side. Your perception is limited by the physics of light,
which does not penetrate the wall, and thus you only obtain limited data and limited information
about the environment. That may be an extreme example, but the point is that all perception is
similarly constrained; it is just a matter of degree. Curiously, in your mind, you do have some idea of
what there is behind the wall (another room, the street, or something else), but this idea is vague
and uncertain. We will see in this chapter why all perception is, to some extent, a similar kind of
guesswork.
Perception as unconscious inference
Yet, AI has recently been making major progress in vision. One reason is that computers have been getting
much faster every year, but that is of course not enough in itself if you don’t know how to program your
computer. The crucial breakthrough in recent computer vision has been the application of neural networks.
Neural networks offer two important advances. First, they enable the processing of vast amounts of data
to be distributed into a large number of processors, which work in parallel and thus can process
the data more easily. The advantages of such distributed and parallel processing are considered
in more detail in Chapter 11. In this chapter, we focus on another advantage, which is that we
know how to use neural networks to learn from big data sets. Learning can alleviate, and to some
extent solve, the problem of incomplete information, such as seeing only a 2D projection of the 3D
world.
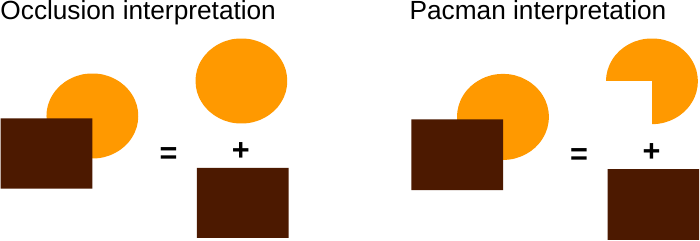
The trick is to learn what the world typically looks like, and to use the learned regularities to complement
the incoming data. Look at the figure on the far left-hand side of Figure 10.2. Here, we tend to perceive a disk
and a square. This is because we immediately assume that the disk actually continues behind the square, it is
just partly occluded (i.e. blocked from view) by the rectangle. In fact, we tend to almost see a whole disk.
There’s nothing wrong with such an assumption, but it does not necessarily follow from the figure.
Alternative interpretations are possible based on this incomplete data. For example, it could be that the
figure actually consists of a square and a “pacman”, as illustrated on the right-hand side of the
figure.
Perceptions such as in this example are usually explained as results of unconscious inference using
prior information. The visual system has learned certain regularities in the outside world—this
is called prior information. For example, contours are typically continuous and smooth; lines are
typically long and straight; objects can be behind or in front of each other. So, in Figure 10.2, the
brain computes that it is very likely that the incomplete disk is actually part of a whole disk, but
we just don’t get visual input on the whole disk because it is blocked. Such a conclusion is made
by neural networks which are outside of our consciousness, thus the process is called unconscious
inference.
The inference in question is also probabilistic: The visual system cannot know for sure whether the edge
of the disk continues behind the square, but it is more likely that it does than that it doesn’t.
That is, the brain cannot make any judgements that are logically necessary and certain about this
picture. The only thing the brain can do is to calculate probabilities and choose the most probable
interpretation.
That is why perception is necessarily uncertain.
Bayesian inference
The probabilistic inference needed in perception takes a particular form where the goal is to determine
causes when observing the effects. The mathematical theory behind such inference was initially
proposed by Thomas Bayes in the 18th century, which is why such inference is often called
Bayesian.
In the case of perception, the “effects” are the patterns of light coming into your eyes, while the “causes” are the
objects and events in the outside world.
Typical scientific models based on physics will tell you what the effects are for given causes. For example,
given an object and its location in your field of vision, you can rather easily compute, by basic physics, what the
light coming from that object to your eyes will be like. But doing the computation backwards is more difficult.
Given that your eye receives certain light patterns, as registered by your sensory organs, how can you know
what went on in the outside world? You have to somehow invert your physical model of the world,
leading to the inverse problems just mentioned. Such problems can be approached by Bayesian
inference, especially in the case where we can only calculate probabilities, which is exactly the case
here.
Bayesian inference tells that the probability for a given cause (given we observe certain effects) is
proportional to the product of two things: First, the probability that such a cause creates the observed effects,
and second, how likely the cause is to occur in general. The first part here is rather obvious: A given cause is
more likely to be responsible for what your sensory organs report if the cause and such sensory input
are compatible, and that cause is likely to produce the observed effects. However, the important
point here is in the second part: A given cause is even more probable if its general probability of
occurrence is large. That is, if the cause has high “prior probability” in the terminology of Bayesian
inference.
Consider the following example. Through your living room window, you get a glimpse of something green
moving on the street. It could have been a green car, or it could have been a Martian (they are all green, as we
all know). Both of these two causes (car or Martian) would produce the same kind of quick flash of something
green moving on the street, or more precisely, some green light briefly entering your eyes. So, the probability of
the effect (green light stimulating your retina) is high for both two causes; let’s say for the sake of argument that
it is equally high in both cases. However, you will not think it is a Martian. The reason is that your brain uses
Bayesian inference and looks at the prior probabilities. The prior probability of a Martian is very
much lower than the prior probability of a green car; the brain knows that in general, it is very
rare to encounter any Martians. Thus, in weighing the probabilities of the different causes, the
green car wins by a wide margin. This inference is possible because the brain has a model of what
the world is typically, or probably, like: Martians are quite rarely encountered, at least on planet
Earth.
Prior information can be learned
Prior information, i.e. a model of what the world is typically like, is central in such unconscious inference, so
where does it come from? The crucial principle in modern AI and neuroscience is that the prior information can
be obtained by learning from data: Learning is thus the basis of perception. Now that may seem like a weird
claim from a biological viewpoint. How could perception possibly be based on learning, given that many animals
see quite well more or less immediately after birth? With human infants, developing proper vision actually takes
several months but that is beside the point. The point here is to understand the different meanings of the word
“learning”.
When I talk about learning here, I mean learning in a very abstract sense where a system adapts its
behaviour and computations to the environment in which it operates, and in particular to the input it receives.
In human perception, such adaptation happens on different levels and time scales: there is both the evolutionary
adaptation and the development of the individual (after birth). These two time scales are very different, but if
we are interested in the final result of learning, we can just lump the two kinds of adaptation together. Likewise,
the optimization procedures are very different: evolution is based on natural selection while individual
development presumably uses something like Hebbian learning—although we don’t understand
the details yet. Again, if we just look at the end result of the combination of those processes, we
can ignore the difference of optimization procedures as well, and simply call this whole process
“learning”. This resolves the paradox of animals being able to perceive things instantly after birth. Their
sensory processing is using all the results of the evolutionary part of learning, and thus even before
having received much input as individuals, their neural networks are capable of some rudimentary
processing.
Neural networks weights contain the prior information
We already saw in Chapter 4 how it is possible to train a neural network from big data sets. The weights in the
network are learned based on minimization of some error function. In the simplest case, the learning algorithm
knows what there is in each image used for training (a cat or a dog) which provides a label or a category, and
then we can use supervised learning. If we want to understand biological vision, though, unsupervised
learning is preferred. This is because the visual system does not really have anybody constantly
giving labels to each input image, which makes supervised learning unrealistic as a theoretical
framework.
Fortunately, Hebbian learning and other methods of unsupervised learning can learn to analyse
images in interesting ways, without any supervision. Intuitively, if the input to neuron A and the
input to neuron B are often rather similar, it is likely that they are somehow signalling the same
thing, and thus they should be processed together, for example by computing their average or
difference.
The results of such learning are stored in the synaptic weights of the neural network. From the viewpoint of
Bayesian perception, we can thus say that the prior information is learned and stored in the form of the weights
connecting the neurons. This allows us to investigate what kind of prior information can be learned from visual
input, by looking at the weights of an artificial neural network trained with ordinary photographs as
input.
If we look at the initial analysis of images done by a neural network with one layer, different learning rules
almost invariably give the same result: the most basic visual regularities are something like short edges or bars.
Figure 10.3 shows some examples. Interestingly, such AI learning leads to processing which is very
similar to the part of the brain that does some of the earliest analysis of incoming images, called the
primary visual cortex. Measurements of many cells in that area reveal that they compute features
which look very much like those in Fig 10.3. Such edges and bars are clearly a very fundamental
property of the structure of images, which is why they are often used in the beginning of image
analysis.
Such edges and bars can be seen as the first stage of the successive “pattern-matching” on which neural network
computation is based. We can actually go further and train a feedforward neural network with many layers to analyse
images.
After successful training, a multi-layer neural network can contain extremely rich prior information about
images. In general, the multi-layer network will be computing increasingly complex features in each
layer.
The features computed by the units in higher layers are no longer simple edges or bars: they are more like some
specific parts of the objects that the network was trained on. They are also more focused on coding the identity
of those parts while ignoring less relevant details such as wherein the image the parts are located. For example, a
neuron in a high layer could respond to a cat head, irrespective of where it is in the input image, and further
ignore details such as the exact shape of the face of the cat. In this sense, such neurons are quite similar to
cells in the inferotemporal cortex, an area in the brain that performs a very high level of image
analysis.
Illusions as inference that goes wrong
We have now seen that the incompleteness of the incoming sensory information can be, to some
extent, alleviated by Bayesian inference. However, this solution is far from perfect—whether we
consider perception in humans or sophisticated AI. Sometimes the perception is blatantly incorrect,
as shown by the phenomenon of visual (or “optical”) illusions. A dramatic example is shown in
Figure 10.4. We tend to see a full triangle in the figure, with three uninterrupted lines as its sides
or edges. In reality, though, the sides of the triangle do not exist in the figure. If you cover the
“pacmans” with your fingers, you see that there is nothing but white space between them. Yet,
most people have a vivid perception of three lines between the pacmans which create a complete
triangle.
This is called an illusion in neuroscience since the sides do not physically exist in the figure; they are simply
imagined by our visual apparatus. Just like the imagination of a full disk in Figure 10.2 we saw earlier, this can
be considered unconscious inference, where your visual system computes the most likely interpretation. The
difference is that here, the interpretation is in clear contradiction with the actual stimulus, or physical reality.
While inferring a full disk in Figure 10.2 seemed smart and would quite probably have been correct in real life,
inferring that there is a full triangle in Figure 10.4 may seem quite stupid, at least after you have checked that
the sides do not really exist. The curious fact is that you cannot really help seeing the triangle in
Figure 10.4.
The theories explained in earlier chapters help us further understand why such illusions occur. A neural
network is trained to accomplish a well-defined task, such as recognizing different objects in photographs.
However, such neural networks are inflexible and only able to solve the problem they are trained for; neural
networks are not general problem-solving machines. In particular, a neural network will not work very well when
the input comes from a different source than what it was trained for. Arguably, the Kanizsa triangle is
something artificial, and different from what you would usually see in real life (where pacmans are quite rare), so
we should not expect the brain’s neural networks to process it appropriately. This is another way of saying that
the brain’s prior information contains assumptions that are typically true in the context where
you usually live, but they are just about probabilities, and might sometimes turn out to be quite
wrong.
At the same time, the dual-system theory explains why it does not help if somebody explains to you that this
is an illusion, or even if you realize that yourself. A logical, symbol-level understanding that there is no triangle
has little effect on the other system, i.e., neural networks, which are mainly in charge of visual
perception.
Attention as input selection
As already mentioned, in real life, any sophisticated perceptual system further faces the problem that there is
simply too much information in the visual field. This problem is very different from the missing information
problem solved by the prior information, as just discussed. In particular, there are often too many things in the
visual input at the same time. There may be many faces, people, buildings, animals, or cars, at the same time,
and it is too difficult to process all of them. This is in stark contrast to current success stories of object
recognition by AI, which are usually obtained in a setting where each input image contains only one object, or at
least one object is much more prominent than the others. Suppose you input an image of a busy street
to such a neural network trained to recognize a single object in an image. Since the input now
contains many objects, features of different kinds will be activated in the neural network, some
related to the perception of people, some related to the perception of buildings, some to cars, and
so on. Many of the features are actually quite similar in different objects: think about two faces
in a crowd, which are quite similar on the level of pixels and even rather sophisticated features.
Various neurons will be activated, but it is impossible to tell which were activated by which face.
It will be very difficult for the AI to make sense of such input and the activations of its feature
detectors.
This problem really arises when the information processing as well as the input data sensors work in a
parallel and distributed mode. Parallel and distributed processing, considered in detail in Chapter 11, usually
means that there are many processors which work simultaneously and independently. Here, the situation is even
more extreme since the input data itself is received from a huge number of sensors, such as pixels in a camera or
cells in the retina. Yet, the principles of parallel and distributed processing are really the same, as
the outputs of such sensors are processed by a large number of small processors, at least in the
brain.
Traditional computer science usually does not deal with this problem. If the input to the computer is mouse
clicks by a human user, the input is quite manageable. Even if a computer handles a very large database, the
situation is different because it follows explicit instructions on what information to retrieve and in what order.
Vision is more like thousands of disk drives simultaneously and forcefully feeding the contents of their databases
to a single computer.
The key to how the brain solves this problem, especially in the case of vision, is the multi-faceted
phenomenon of attention. In the most basic case, the visual system of many animals, including humans, selects
just one part of the input for further processing. As we say in everyday English, the animal only “pays
attention” to one object at a time, whether it is a face seen on the street, or some object it is trying to
manipulate.
The simplest form of such selective attention is that you just wipe out everything else in the
visual field, except for one object. In Figure 10.5, we see a photograph and an attentional selection
template, which shows how only the main object of interest in the figure is found and selected. The
results of such computation can be used to simply blank out everything else except for the main
object.
Such a form of attentional selection is also called “segmentation”. Now, if you input an image that contains only
this one object to the neural network, the recognition will be much easier. The most amazing kind of attentional
selection that our brains can accomplish must be finding individual faces in a crowd. Face processing is
evolutionarily extremely important, so there are specialized areas in the human brain for processing just faces
(monkeys have them too).
Performing such segmentation is not easy: using attentional mechanisms in AI and robots is an emerging topic, and we
still don’t know very well how to do it. However, like so many other functions related to intelligence, it may be possible to
learn it. In
fact, such selection seems to be happening in many different parts of the brain and in many different ways. In a sense, it
is a reflection of the ubiquity of parallel processing in the brain, which necessitates various forms of input selection all
over the brain.
The key point in attention is that it leads to a bottleneck in the processing. In the example just given, only
the one single object left in the image is given to further processing, including the final pattern recognition
system. So, only one object can be recognized at a time, since all the others are wiped out. It is often said in
cognitive neuroscience that “attentional resources are limited”, and here we see one illustration of that principle:
if you pay attention to one thing, you will necessarily tend to ignore everything else. This, in its turn,
increases uncertainty since you don’t know much about those things you are not paying attention
to.
Subjectivity and context-dependence of perception
An important consequence of the uncertainty of perception is its subjectivity: I see one thing, and you may see
something different. Being based on unconscious inference using prior information, perception is subjective if
different people or agents have different priors. Then they will interpret the incomplete incoming information in
different ways.
The priors used in human perception actually contain many different parts. There is one rather permanent
and universal component, shared by all humans, and probably many animals. It includes those general
regularities that can typically be found by training artificial neural networks. But another component in
the prior is more individual and depends on the experience of the agent (animal, human or AI).
When an agent observes things happening, ideally it will incorporate all the new observations into
its prior—possibly after performing some kind of attentional selection. If it didn’t, it would be
wasting valuable data that it has collected on the world. It is this individual part of the prior,
based on their own experiences, that makes the priors different from one agent to another. Each
agent may even be living in a different environment; they may spend their time in very different
occupations. So, it is clearly useful that the prior is different from one agent to another. But this
necessarily implies that perception will be different as well. You don’t see exactly the same thing as your
friends, not to even mention your robot. This might not be such a serious problem if the agent
understood the subjectivity of perception well enough. However, such understanding often escapes even
humans.
There is even a further component in the prior, which depends on the context, e.g., where the agent is at the
moment of perception. If you’re at home, you expect to see certain kinds of things, and if you’re walking on the street,
you expect to see other kinds of things. This leads to dependence of perception on the context, even for the same
agent.
These limitations of perception reflect the limitations of categories discussed in Chapter 7. Categorization is
usually based on perception, so if perception is subjective and context-dependent, the categories inherit those
properties as well.
Perception is made even more subjective by the selection of incoming information by attentional
mechanisms. Attention has a huge impact not only on the immediate perception in the agent, but also on the
model it learns on the world. Fundamentally, attentional mechanisms choose the data that is input into the
learning system. Anything not attended is pretty much ignored and not used in learning. As our brain “creates
our world” in the sense of reconstructing it from sensory input, that creation is thus strongly influenced by
attentional mechanisms.
Reward loss as mere percept
A crucial insight that this view on perception gives to suffering is that its causes are subjective and generally
uncertain: they may be based on faulty inference. In particular, reward loss is just another percept (i.e. a result
of the process of perception). It is based on solving an inverse problem using prior information to compute a
percept of the obtained reward.
Misperceptions of rewards may be particularly common when perception of other people’s reactions are
involved. You might perceive the facial expression of your friend as angry, and register some negative reward as
resulting from your actions. But perhaps your friend just had a bad headache and his face reflected that; taking
the uncertainty of perception into account should help you behave in a more appropriate way towards
him.
An extreme example of misperception of reward is found with some drugs of abuse. They
feel good and you perceive a reward on a biological level. Yet, such perception has no real
basis: The drug merely misleads your brain into perceiving a reward by perturbing its
metabolism.
The situation is even more complicated here since the agent also computes the expected reward based on the
information it has at its disposal and using the available computational capacities. Thus, there
seem to be two different ways in which uncertainty in perception affects the computation of reward
loss: the obtained reward may be perceived wrong, or the computation of expected reward may go
wrong.
Both are just logical consequences of computation performed with limited resources and limited
data. Ultimately, a reward loss may even be illusory in the sense that one is perceived but it is
merely a mental construct. One way to remedy the situation is that we should actually consider
perceived reward loss instead of any objectively defined reward loss, since the agent can never know
with certainty what the reward loss was. (We will postpone the details of such a re-definition to
Chapter 13.)
Ancient philosophers on perception
The uncertainty and subjectivity of perception were discussed by several ancient philosophers. In ancient Greece, the
Skeptic school was particularly prominent in pointing out the limits of human knowledge, including the relativity of
perception. The Pyrrhonian branch was fond of giving examples where different people perceive the same thing
differently:
When we press the eye from the side, the forms and shapes and sizes of the objects we see
appear elongated and narrow.
The colour of our skin is seen as different in warm air and in cold, and we cannot say what
our colour is like in its nature, but only what it is like as observed together with each of these
[circumstances].
Such uncertainty leads the skeptic to adopt an attitude of not making any judgements on external
objects:
So, since so much anomaly has been shown in objects (...), we shall not be able to say what
each existing object is like in its nature, but only how it appears (...) therefore, it is necessary
for us to suspend judgement on the nature of external existing objects.
A Japanese Yogācāra-inspired poem beautifully describes a scene where different agents have very different interpretations of the
same sensory input:
At the clapping of hands,
the carp come swimming for food;
The birds fly away in fright, and
A maiden comes carrying tea—
Sarusawa Pond
When somebody claps his hands by the famous Sarusawa Pond in Nara, Japan, the carps interpret it as a call for
feeding; the birds are scared of the noise and flee; while a maid of a near-by inn thinks a customer is calling for
her.
It is perhaps easy to admit that an animal or a robot sees things differently from yourself, either in a more
primitive way, or in a superhuman way. Yet, it is notoriously difficult for humans to admit that two people can
see the same thing in different ways, and that both ways can be equally valid. But there is something
even more challenging; there is an even more difficult implication of the theories discussed in this
chapter. It is the general idea that all our perceptions are actually just interpretations, or beliefs,
or inferences, instead of revealing an objective truth. In AI theory, it is never claimed that the
agent knows anything; the very concept of knowing is conspicuously absent in that theory. All
an AI agent has is beliefs, and those are usually expressed in terms of probabilities, lacking any
certainty.
When you take this line of thinking further, you may arrive at the idea that all we believe or pretend to
“know” is based on our perceptions, and thus inherits the uncertainty and the subjectivity of perception. In fact,
one could say that my perception defines my world. This may actually be rather obvious to anybody who
programs a sensory system in an AI. Such ideas are often associated with Asian philosophical systems such as
Mahayana Buddhism, especially the Yogācāra school and later schools drawing on those ideas, including
Zen. Yet, those
ideas have also been beautifully expressed in the West, where their foremost proponent may have been David Hume
who wrote:
Let us chase our imagination to the heavens, or to the utmost limits of the universe; we
never really advance a step beyond ourselves, nor can conceive any kind of existence, but
those perceptions, which have appeared in that narrow compass. This is the universe of the
imagination, nor have we any idea but what is there produced.
We will see these deep points re-iterated and expanded in later chapters, especially Chapter 12.