This is the very core of XSL transformations: Read carefully!!!
Every node in the input XML document(s) is assigned a type by the
DOM builder class. This type is an integer value which represents the
element, so that for instance all <bob> elements in the
input document will be given type 7 and can be referred to by using
that integer. These types can be used for lookups in the
namesArray table to get the actual
element name (in this case "bob"). These types are referred to as
external types or DOM types, as they are types known only
to the DOM and the DOM builder.
Similarly the translet assignes types to all element and attribute names
that are referenced in the stylesheet. These types are referred to as
internal types or translet types.
It is not very probable that there will be a one-to-one mapping between
internal and external types. There will most often be elements in the DOM
(ie. the input document) that are not mentioned in the stylesheet, and
there could be elements in the stylesheet that do not match any elements
in the DOM. Here is an example:
 | | |
|
<?xml version="1.0"?>
<xsl:stylesheet version="1.0" xmlns:xsl="blahblahblah">
<xsl:template match="/">
<xsl:for-each select="//B">
<xsl:apply-templates select="." />
</xsl:for-each>
<xsl:for-each select="C">
<xsl:apply-templates select="." />
</xsl:for-each>
<xsl:for-each select="A/B">
<xsl:apply-templates select="." />
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>
| |
| | |
In this stylesheet we are looking for elements <B>,
<C> and <A>. For this example we can assume
that these element types will be assigned the values 0, 1 and 2. Now, lets
say we are transforming this XML document:
| | |
|
<?xml version="1.0"?>
<A>
The crocodile cried:
<F>foo</F>
<B>bar</B>
<B>baz</B>
</A>
| |
| | |
This XML document has the elements <A>,
<B> and <F>, which we assume are assigned the
types 7, 8 and 9 respectively (the numbers below that are assigned for
specific element types, such as the root node, text nodes, etc.). This
causes a mismatch between the type used for <B> in the
translet and the type used for <B> in the DOM. Th
DOMAdapter class (which mediates between the DOM and the translet) has been
given two tables for convertint between the two types; mapping for
mapping from internal to external types, and reverseMapping for
the other way around.
The translet contains a String[] array called
namesArray. This array will contain all the element and attribute
names that were referenced in the stylesheet. In our example, this array
would contain these string (in this specific order): "B",
"C" and "A". This array is passed as one of the
parameters to the DOM adapter constructor (the other adapter is the DOM
itself). The DOM adapter passes this table on to the DOM. The DOM has
a hashtable that maps known element names to external types. The DOM goes
through the namesArray from the DOM sequentially, looks up each
name in the hashtable, and is then able to map the internal type to an
external type. The result is then passed back to the DOM adapter.
The reverse is done for external types. External types that are not
interesting for the translet (such as the type for <F>
elements in the example above) are mapped to a generic "ELEMENT"
type 3, and are more or less ignored by the translet.
It is important that we separate the DOM from the translet. In several
cases we want the DOM as a structure completely independent from the
translet - even though the DOM is a structure internal to XSLTC. One such
case is when transformations are offered by a servlet as a web service.
Any DOM that is built should potentially be stored in a cache and made
available for simultaneous access by several translet/servlet couples.
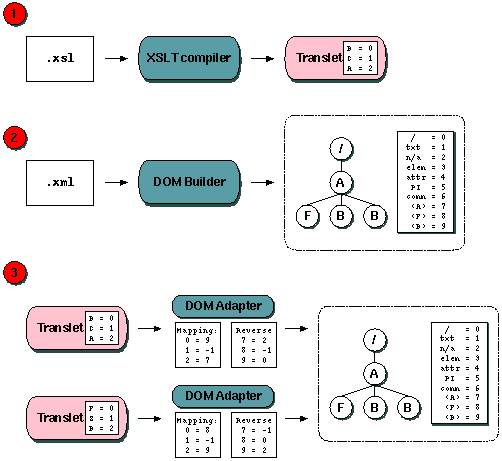
Figure 1: Two translets accessing a single dom using different type mappings