Database management, fall 2004, Exercises 5 (2.12.2004)
1
Let's consider the join R 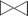 R.a=S.b S.
Costs are measured as the number of disk accesses. Disk operations needed in writing the result are not
counted.
Page size in 4KB.
Table R has 10,000 rows. Each page contains 10 rows.
Table S has 2000 rows, 10 rows in each page.
Column b is the primary key of S.
Both tables are stored as piles without indexes.
Buffer space is available for 52 pages.
R.a=S.b S.
Costs are measured as the number of disk accesses. Disk operations needed in writing the result are not
counted.
Page size in 4KB.
Table R has 10,000 rows. Each page contains 10 rows.
Table S has 2000 rows, 10 rows in each page.
Column b is the primary key of S.
Both tables are stored as piles without indexes.
Buffer space is available for 52 pages.
(a) What is the cost of this join when it is done using the block nested loop join technique?
How does reduction of buffer space affect the costs?
(b) What is the cost of this join when it is done using the merge join technique?
How much can we reduce the needed buffer space without increasing the costs?
(c) What is the cost of this join when it is done using the hash join technique?
How does the reduction of buffer space affect the costs with this technique?
2 Consider the join of task 1.
(a) When you may increase the buffer space, what would be the lowest cost join and
how much buffer space would be needed?
(b) How many rows are in the result of this join at least, and at most,
and how many pages must be written in the result file?
(c) How would your answer to task (b) change, if you knew that
column a of R is a foreign key that refers to S and null values are not allowde in it?
3. The database contains information about the employees, departments and their financial affairs. It has the following schema.
Dept(did: integer, dname: char(20), floor: integer, phone: char(10));
Finance(did: integer, budget: real, sales: real, expenses: real);
Consider the query:
FROM Emp E, Dept D, Finance F
WHERE E.did = D.did AND D.did = F.did AND D.floor = 1
AND E.sal >= 59000 AND E.hobby = 'yodeling';
(a) Express the query in relational algebra and draw a query tree for it.
(b) Optimize the query (use rules) and draw the optimized query tree.
(c) Explain briefly what indexes would improve the effiency of the query execution.
4. The database contains data about parts and their suppliers. It has the following schema:
Supply(sid: integer ->Supplier, pid: integer->Parts);
Parts(pid: integer, pname: char(20), price: real);
Consider the query:
FROM Suppliers S, Parts P, Supply Y
WHERE S.sid = Y.sid AND Y.pid = P.pid AND
S.city = 'Madison' AND P.price <= 1,000;
(a) Express the query in relational algebra and draw its query tree.
(b) What information about the tables is needed in order to build up a good execution plan?
(c) Optimize the query and draw the optimized query tree. Make assuptions
of the missing statistic information and estimate the cost of this query
(there are about 2000 parts).
.
5. Consider the database schema
Material(courseid: integer->Course, bookid: integer ->Books);
Books(bookid: integer, name: char(40));
and the query:
FROM Books b, Material m, Course c
WHERE c.courseid = m.courseid AND c.name = 'Database Management' AND
m.bookid = b.bookid;
Let's assume that table Course has 6000 rows. Table Material has 12000 rows, and table
Books 24000 rows. Page size is 4KB. 20 buffer frames are available.
(a) How many rows are in the result of this query?
(b) Express the query in relational algebra and draw its query tree.
(c) Optimize the query and draw the optimized query tree.
(d) Determine the implementation technique for the operations. Tables are stored as piles and
the are dense B+ -tree structured indexes for columns Course.name, Course.courseid,
Material.courseid, and Book.bookid.
How many data page accesses are needed?