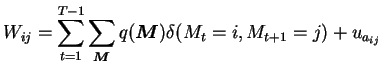MacKay showed in [39] how ensemble learning can be applied to learning of HMMs with discrete observations. With suitable priors for all the variables, the problem can be solved analytically and the resulting algorithm turns out to be a rather simple modification of the Baum-Welch algorithm.
MacKay uses Dirichlet distributions as priors for the model parameters
![]() . (See Appendix A for the definition of
the Dirichlet distribution and some of its properties.) The
likelihood of the model is discrete with respect to all the parameters
and the Dirichlet distribution is the conjugate prior of such a
distribution. Because of this, the posterior distributions of all the
parameters are also Dirichlet. The update rule for the parameters
. (See Appendix A for the definition of
the Dirichlet distribution and some of its properties.) The
likelihood of the model is discrete with respect to all the parameters
and the Dirichlet distribution is the conjugate prior of such a
distribution. Because of this, the posterior distributions of all the
parameters are also Dirichlet. The update rule for the parameters
![]() of the Dirichlet distribution of the transition probabilities
is
of the Dirichlet distribution of the transition probabilities
is
The posterior distribution of the hidden state probabilities turns out
to be of exactly the same form as the likelihood in
Equation (4.6) but with ![]() replaced with
replaced with
![]() and
similarly for
and
similarly for ![]() and
and ![]() . The required expectations over
the Dirichlet distribution can be evaluated as in
Equation (A.13) in
Appendix A.
. The required expectations over
the Dirichlet distribution can be evaluated as in
Equation (A.13) in
Appendix A.