 Xalan-J 2.0 Design
Xalan-J 2.0 Design
Xalan-J 2.0 Design
Xalan-J 2.0 DesignAuthor: Scott Boag
State: In Progress
This document presents the basic design for Xalan-J 2.0, which is a refactoring and redesign of the Xalan-J 1.x processor. This document will expand and grow over time, and is also incomplete in some sections, though hopefully overall accurate. The reader should be able to get a good overall idea of the internal design of Xalan, and begin to understand the process flow, and also the technical challanges.
The main goals of this redesign are to:
The techniques used toward these goals are to:
The goals are not:
How well we've achieved the goals will be measured by feedback from the Xalan-dev list, and by software metrics tools.
Please note that the diagrams in this design document are meant to be useful abstractions, and may not always be exact.
These are the concrete general requirements of Xalan, as I understand them, and covering both the Java and C++ versions. These requirements have been built up over time by experience with product groups and general users.
The following diagram shows the XSLT abstract processing model. A transformation expressed in XSLT describes rules for transforming a Source Tree into a result tree. The transformation is achieved by associating patterns with templates. A pattern is matched against elements in the source tree. A template is instantiated to create part of the result tree. The result tree is separate from the source tree. The structure of the result tree can be completely different from the structure of the source tree. In constructing the result tree, elements from the source tree can be filtered and reordered, and arbitrary structure can be added.
The term "tree", as used within this document, describes an abstract structure that consists of nodes or events that may be produced by XML. A Tree physically may be a DOM tree, a series of well balanced parse events (such as those coming from a SAX2 ContentHander), a series of requests (the result of which can describe a tree), or a stream of marked-up characters.
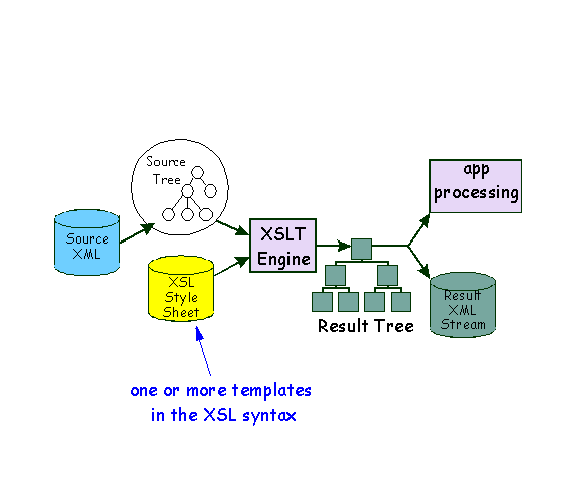
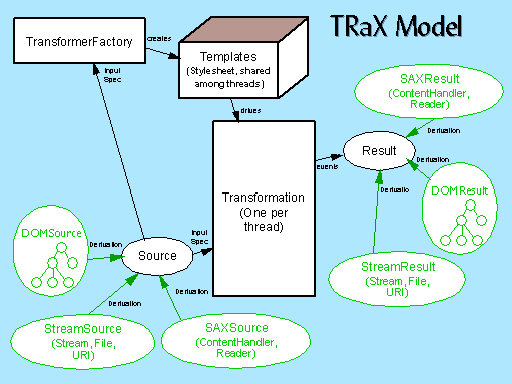
The primary interface for Xalan 2.0 external usage is defined in the javax.xml.transform interfaces. These interfaces define a standard and powerful interface to perform tree-based transformations.
The internal architecture of Xalan 2.0 is divided into four major modules, and various smaller modules. The main modules are:
org.apache.xalan.processororg.apache.xalan.templatesorg.apache.xalan.transformerorg.apache.xpathIn addition to the above modules, Xalan implements the javax.xml.transform interfaces, and depends on the SAX2 and DOM packages.
There is also a general utilities package that contains both XML utility classes such as QName, but generally useful classes such as StringToIntTable.
In the diagram below, the dashed lines denote visibility. All packages access the SAX2 and DOM packages.
![]()
In addition to the above packages, there are the following additional packages:
org.apache.xalan.clientorg.apache.xalan.extensionsorg.apache.xalan.liborg.apache.xalan.resorg.apache.xalan.traceorg.apache.xalan.xsltA more conceptual view of this architecture is as follows:
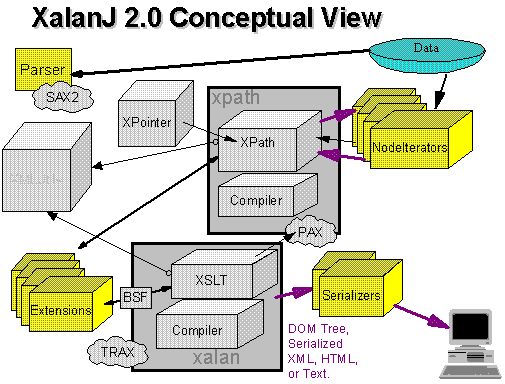
The org.apache.xalan.processor module implements the
javax.xml.transform.TransformerFactory interface, which provides a
factory method for creating a concrete Processor instance, and provides methods
for creating a javax.xml.transform.Templates instance, which, in
Xalan and XSLT terms, is the Stylesheet. Thus the task of the process module is
to read the XSLT input in the form of a file, stream, SAX events, or a DOM
tree, and produce a Templates/Stylesheet object.
The overall strategy is to define a schema in that dictates the legal structure for XSLT elements and attributes, and to associate with those elements construction-time processors that can fill in the appropriate fields in the top-level Stylesheet object, and also associate classes in the templates module that can be created in a generalized fashion. This makes the validation object-to-class associations centralized and declarative.
The schema's root class is
org.apache.xalan.processor.XSLTSchema, and it is here that the
XSLT schema structure is defined. XSLTSchema uses
org.apache.xalan.processor.XSLTElementDef to define elements, and
org.apache.xalan.processor.XSLTAttributeDef to define attributes.
Both classes hold the allowed namespace, local name, and type of element or
attribute. The XSLTElementDef also holds a reference to a
org.apache.xalan.processor.XSLTElementProcessor, and a sometimes a
Class object, with which it can create objects that derive from
org.apache.xalan.templates.ElemTemplateElement. In addition, the
XSLTElementDef instance holds a list of XSLTElementDef instances that define
legal elements or character events that are allowed as children of the given
element.
The implementation of the javax.xml.transform.TransformerFactory
interface is in org.apache.xalan.processor.TransformerFactoryImpl,
which creates a org.apache.xalan.processor.StylesheetHandler
instance. This instance acts as the ContentHandler for the parse events, and is
handed to the org.xml.sax.XMLReader, which the StylesheetProcessor
uses to parse the XSLT document. The StylesheetHandler then receives the parse
events, which maintains the state of the construction, and passes the events on
to the appropriate XSLTElementProcessor for the given event, as dictated by the
XSLTElementDef that is associated with the given event.
The org.apache.xalan.templates module implements the
javax.xml.transform.Templates interface, and defines a set of
classes that represent a Stylesheet. The primary purpose of this module is to
hold stylesheet data, not to perform procedural tasks associated with the
construction of the data, nor tasks associated with the transformation itself.
The base class of all templates objects that are associated with an XSLT element is the ElemTemplateElement object, which in turn implements UnImplNode. A ElemTemplateElement object must be immutable once it's constructed, so that it may be shared among multiple threads concurrently. Ideally, a ElemTemplateElement should be a data object only, and be used via a visitor pattern. However, in practice this is impractical, because it would cause too much data exposure and would have a significant impact on performance. Therefore, each ElemTemplateElement class has an execute method where it performs it's transformation duties. A ElemTemplateElement also knows it's position in the source stylesheet, and can answer questions about current namespace nodes.
A StylesheetRoot, which implements the
Templates interface, is a type of StylesheetComposed,
which is a Stylesheet composed of itself and all included
Stylesheet objects. A StylesheetRoot has a global
imports list, which is a list of all imported StylesheetComposed
instances. From each StylesheetComposed object, one can iterate
through the list of directly or indirectly included Stylesheet
objects, and one call also iterate through the list of all
StylesheetComposed objects of lesser import precedence.
StylesheetRoot is a StylesheetComposed, which is a
Stylesheet.
Each stylesheet has a set of properties, which can be set by various
means, usually either via an attribute on xsl:stylesheet, or via a top-level
xsl instruction (for instance, xsl:attribute-set). The get methods for these
properties only access the declaration within the given Stylesheet
object, and never takes into account included or imported stylesheets. The
StylesheetComposed derivative object, if it is a root
Stylesheet or imported Stylesheet, has "composed"
getter methods that do take into account imported and included stylesheets, for
some of these properties.
The Transformer module is in charge of run-time transformations. The TransformerImpl object, which implements the TrAX Transformer interface, and has an association with a StylesheetRoot object, begins the processing of the source tree (or provides a ContentHandler reference via theSourceTreeHandler), and performs the transformation. The Transformer package does as much of the transformation as it can, but element level operations are generally performed in the ElemTemplateElement.execute(...) methods.
Result Tree events are fed into a ResultTreeHandler object, which acts as a layer between the direct calls to the result
tree content handler (often a Serializer), and the Transformer. For one thing,
we have to delay the call to
startElement(name, atts) because of the
xsl:attribute and xsl:copy calls. In other words,
the attributes have to be fully collected before you
can call startElement.
Other important classes in this package are:
Counter class does incremental counting for support of xsl:number.
This class stores a cache of counted nodes (m_countNodes).
It tries to cache the counted nodes in document order...
the node count is based on its position in the cache list. The CountersTable class is a table of counters, keyed by ElemNumber objects, each
of which has a list of Counter objects.Even though the following modules are defined in the org.apache.xalan package, instead of the transformer package, they are defined in this section as they are mostly related to runtime transformation.
The Stree module implements the default Source Tree for Xalan, that is to be transformed. It implements read-only DOM2 interfaces, and provides some information needed for fast transforms, such as document order indexes. It also attempts to allow an incremental transform by launching the transform on a secondary thread as soon as the SAX2 StartDocument event has occurred. When the transform requests a node, and the node is not present, the getFirstChild and GetNextSibling methods will wait until the child node has arrived, or an endElement event has occurred.
Note that the secondary thread is an issue. It would be better to do the same thing as described above on a single thread, but using the parser in 'pull' mode, or simply with a parseNext method so the parse would occur in blocks. However, this model would only be possible
This kind of incrementality is not perfect because it still requires an entire source tree to be concretely built. There have been a lot of good discussions on the xalan-dev list about how to do static analysis of a stylesheet, and be able to allocate only the nodes needed by the transform, while they are needed (or not allocate source objects at all).
XML serialization is a term used for turning a tree or set of events into a stream, and should not be confused with Java object serialization. The Xalan serializers implement the ContentHandler to turn parser events coming from the transform, into a stream of XML, HTML, or plain text. The serializers also implement the Serializer which allows the transform process to set XSLT output properties and the output stream or Writer.
This package contains an implementation of Xalan Extension Mechanism, which uses the Bean Scripting Framework. The Bean Scripting Framework (BSF) is an architecture for incorporating scripting into Java applications and applets. Scripting languages such as Netscape Rhino (Javascript), VBScript, Perl, Tcl, Python, NetRexx and Rexx can be used to augment XSLT's functionality. In addition, the Xalan extension mechanism allows use of Java classes. See the Xalan-J 2 extension documentation for a description of using extensions in a stylesheet. Please note that the W3C XSL Working Group is working on a specification for standard extension bindings, and this module will change to follow that specification.
[More needed... -sb]
This module is pulled out of the Xalan package, and put in the org.apache package, to emphasize that the intention is that this package can be used independently of the XSLT engine, even though it has dependencies on the Xalan utils module.
The XPath module first compiles the XPath strings into expression trees, and then executes these expressions via a call to the XPath execute(...) function.
Major classes are:
XObject execute(XPathContext xctxt, Node contextNode,
PrefixResolver namespaceContext).The general architecture of the XPath module is divided into the compiler, and categories of expression objects.
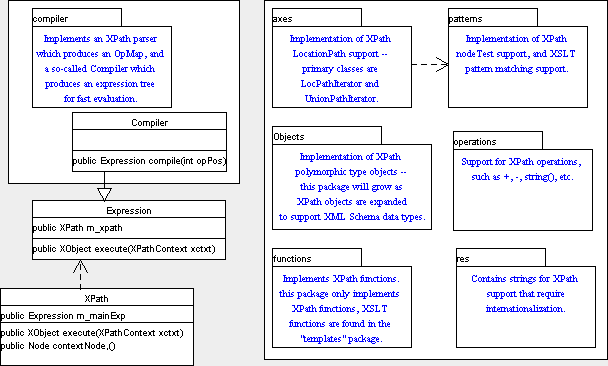
The most important module is the axes module. This module implements the DOM2 NodeIterator interface, and is meant to allow XPath clients to either override the default behavior or to replace this behavior.
The LocPathIterator and UnionPathIterator classes implement the NodeIterator interface, and polymorphically use AxesWalker derived objects to execute each step in the path. The whole trick is to execute the LocationPath in depth-first document order so that nodes can be found without necessarily looking ahead or performing a breadth-first search. Because a document order depth-first search requires state to be saved for many expressions, the default operations create "Waiter" clones that have to wait while the main AxesWalkers traverses child nodes (think carefully about what happens when a "//foo/baz" expression is executed). Optimization is done by implementing specialized iterators and AxesWalkers for certain types of operations. The decision as to what type of iterator or walker will be created is done in the WalkerFactory class.
[Frankly, the implementation of the default AxesWalker, with it's waiters, is the one totally incomprehensible part of Xalan. It gets especially difficult because you can not look to the node ahead. I would be very interested if any rocket scientists out there can come up with a better algorithm.]
An important part of the XPath design in both Xalan 1 and Xalan 2, is to enable database connections to be used as drivers directly to the XPath LocationPath handling. This allows databases to be directly connected to the transform, and be able to take advantage of internal indexing and the like. While in Xalan 1 this was done via the XLocator interface, in Xalan 2 this interface is no longer used, and has been replaced by the DOM2 NodeIterator interface. An application or extension should be able to install their own NodeIterator for a given document.
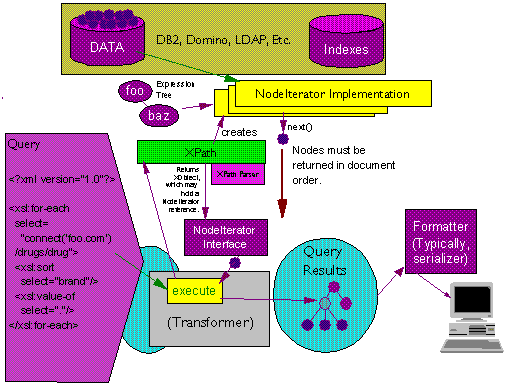
[More to do]
This package contains general utilities for use by both the xalan and xpath packages.
We are doing some work on compiling stylesheet objects to Java. This is a work in progress, and is not meant for general use yet. For the moment, we are writing out Java text files, and then compiling them to bytecodes via javac, rather than directly producing bytecodes. The CompilingStylesheetProcessor derives from TransformerFactoryImpl to produce these classes, which are then bundled into a jar file. For the moment the full Xalan jar is required, but we're looking at ways to only use a subset of Xalan, so that only a minimal jar would be required.
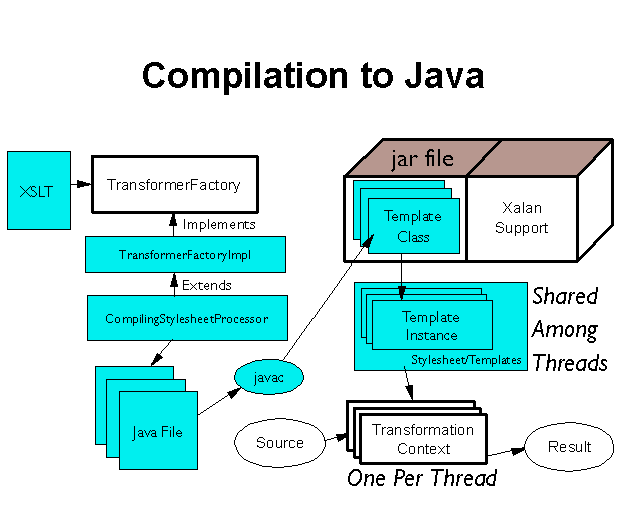
This section enumerates some optimizations that we're planning to do in future versions of Xalan.
Likely near term optimizations (next six months?):
Likely longer term optimizations (12-18 months?):
This section documents the coding conventions used in the Xalan source.