Let's study the following sentence (again):
Last night in San Clemente District, 9 km north of Pisco, a group of terrorists dynamited machinery belonging to Albolones Peruanos, Inc.
This time we study the use of WordNet, a lexical database for the English language. There is an online search facility at http://www.cogsci.princeton.edu/cgi-bin/webwn1.7.1.
- Give words of the sample sentence above to WordNet and study what kind of information is available.
- How could you use this information in the IE process?
- Do you see problems in using WordNet for IE?
In this exercise we learn how to use finite transducers (suom. äärellinen transduktori) to extract information from text. A finite transducer is like a finite automaton, but it can emit an output string during each transition made.
Assume our dictionary contains (among other things; you may consider here everything you found in WordNet or what a language analyzer like Conexor FDG or ENGTWOL might give) the following entries:
Berlin: ProperName Maria: ProperName work: Verb at; Prep Inc.: CompAbbr ...
Given the dictionary, in the lexical analysis phase, all the words have got some kind of label (Noun, Verb, ProperName,..). Let also any word that is unknown to the dictionary and that starts with an uppercase letter get a label 'UnknownCap', and that a comma has been translated to 'Comma'. Assume that all the words have been replaced by their labels. Now we can try to recognize company names (CompanyName) by the following regular expression:
(ProperName | UnknownCap)+ Comma? CompAbbr
This expression says that a sequence of words/terms is a CompanyName if there is first a nonempty sequence of words that are either recognized to be proper names (e.g. found in the dictionary of names) or that are unknown words starting with a capitalized letter. This sequence may be followed by a comma, and finally there has to be a word recognized as a company abbreviation (like 'Inc.'). In our sentence, the phrase 'Albolones Peruanos, Inc.' would be recognized as a CompanyName using this rule.
But our goal is to replace the recognized sequence by 'CompanyName' and leave the rest of the sentence as such. We can first model the whole sentence that contains a CompanyName as follows (let 'c' denote any word):
c* (ProperName | UnknownCap)+ Comma? CompAbbr c*
Now we can construct a (non-deterministic) transducer that recognizes the sequence that corresponds to a CompanyName and replaces this sequence with 'CompanyName', but leaves all the other words as such (UnC = UnknownCap; PN = ProperName; CAbb = CompAbbr; CN = CompanyName; e = an empty string):
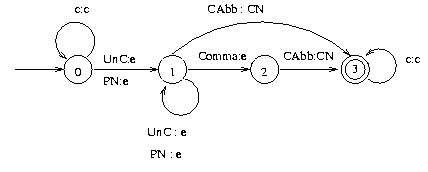
Note that the transducer is non-deterministic: as c means any word, it matches also any UnknownCap. Thus, if an UnknownCap appears in a sentence, there are two alternative directions to move from state 0: state 0 or state 1. All paths are followed, and if some path ends up in a final state (here state 3), a match is found. If there is not any successful path, also nothing is output by the transducer. For instance, assume we have the following sentence:
Maria Carrasco works at Albolones Peruanos, Inc.
and its representation after the lexical analysis phase:
ProperName UnknownCap Verb Prep UnknownCap UnknownCap Comma CompAbbr
Now our transducer that tries to find CompanyNames finds first ProperName and may move to state 1. With the next UnknownCap the transducer may stay in state 1, but for the Verb that comes next, there is no transition, so this path fails. But the transducer could have stayed in state 0 (= interpreted all the words as 'c') until the second UnknownCap has been seen, and then moved to state 1. This choice would have lead to a successful path. After this translation, the sentence would be:
ProperName UnknownCap Verb Prep CompanyName
There would probably also be another transductor that replaces sequences of ProperName and UnknownCap with one ProperName. The sentence above would be given to this transductor, and after the work of both transductors, the sentence would be:
ProperName Verb Prep CompanyName
Note that here, to keep it simple, all the knowledge of the words has been thrown away, but in practice, we would keep the knowledge of e.g. that the Verb was 'work' somewhere and use this knowledge in the later IE stages.
And now your task: Formulate a regular expression and a transducer that translates the following sequences of text into NounPhrase and Location, respectively. You can make assumptions (like I made above) about the features of words known, that is, how the sentences look like after the lexical analysis phase.
NounPhrase a group of terrorists Location in San Clemente District 9 km north of Pisco
You can present the transducer (if you don't want to draw) as a set of triples (state1, state2, input:output), like
(s0, s0, c:c) (s0, s1, UnC:e) (s1, s1, UnC:e) (s1, s2, Comma:e) (s1, s3, CAbb:CN) etc.
More information:
You can read more about finite transducers and translation on the page: Xeroxin Äärellisten Automaattien Kääntäjä / Xerox Finite-State Compiler / Compilateur ŕ États Finis de Xerox / Xerox-Compiler für Endliche Automaten
-
FASTUS system (SRI International); and paper FASTUS: A Cascaded Finite-State Transducer for Extracting Information from Natural-Language Text