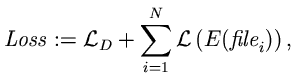
3 Concepts: Information | Projects
1) April 15, 24:00
2) April 24, 24:00
3) April 29, 24:00
Final) May 6, 24:00
Documentation) May 14, 9:00
| R O U N D 1 | |
|---|---|
| TOTAL BYTES | |
| 1. Team Heino | 20'903 |
| 2. Team Kääriäinen | 22'567 |
| 3. Team Haapasalo | 28'088 |
| 4. Team Päiväniemi | 34'272 |
| 5. Team Aunimo | 35'552 |
| 6. Team Mäkelä | 42'256 |
For Round 2, the curve1 and curve2 data sets have been enlarged and a new data set, yeast, has been introduced. In addition, the data set extra contains data submitted by Team Heino (1475 bytes) and Team Kääriäinen (643 bytes).
» Download updated data for Round 2.
| R O U N D 2 | |
|---|---|
| TOTAL BYTES | |
| 1. Team Heino | 139'440 |
| 2. Team Kääriäinen | 145'897 |
| 3. Team Mäkelä | 153'482 |
| 4. Team Haapasalo | 156'586 |
| 5. Team Päiväniemi | 185'395 |
| 6. Team Aunimo | - |
Team Heino and Team Kääriäinen have kept the lead. For Round 3 they will submit 3416 and 188 bytes, respectively. No new data sets for Round 3.
» Download updated data and
scripts for Round 3.
| R O U N D 3 | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| DEC. | curve1 | curve2 | extra | info | letter | mush. | yeast | TOTAL | |
| 1. Team Heino | 3'045 | 12'374 | 13'114 | 189 | 669 | 1'167 | 1 | 107'068 | 137'627 |
| 2. Team Kääriäinen | 1'868 | 13'449 | 14'303 | 3'618 | 698 | 3'075 | 774 | 108'071 | 145'856 |
| 3. Team Mäkelä | 2'914 | 13'286 | 13'947 | 3'605 | 483 | 6'405 | 1 | 108'006 | 148'647 |
| 4. Team Haapasalo | 1'921 | 15'013 | 15'296 | 3'608 | 1'187 | 5'937 | 622 | 107'960 | 151'544 |
| 5. Team Päiväniemi | 539 | 22'297 | 21'726 | 3'615 | 668 | 12'568 | 1'397 | 124'071 | 186'881 |
| 6. Team Aunimo | 805 | 22'427 | 22'041 | 3'627 | 707 | 12'580 | 1'375 | 127'861 | 191'423 |
Team Heino is still going on strong (3208 bytes of data submitted). There seems to be a good race for the second place. For the Final Round, the (largish) data set forest has been introduced. We'll see if it changes the ranking. Also, detailed results may stir the pot.
» Download updated data (data sets forest
and extra) for the Final Round.
» Download data set extra for the Final
Round.
| F I N A L R O U N D | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| DEC. | curve1 | curve2 | extra | forest | info | letter | mush. | yeast | TOTAL | |
| 1. Team Heino | 3'548 | 12'374 | 13'114 | 1 | 21'159 | 669 | 1'167 | 1 | 107'068 | 159'101 |
| 2. Team Kääriäinen | 3'756 | 12'615 | 13'394 | 3'209 | 21'366 | 696 | 2'008 | 0 | 107'356 | 164'400 |
| 3. Team Mäkelä | 3'077 | 13'205 | 13'867 | 3'209 | 22'088 | 502 | 6'137 | 1 | 107'049 | 169'135 |
| 4. Team Haapasalo | 2'384 | 14'315 | 15'201 | 3'209 | 24'196 | 708 | 5'362 | 1 | 107'953 | 173'329 |
| 5. Team Aunimo | 4'841 | 16'263 | 16'272 | 3'232 | 32'705 | 709 | 12'583 | 21 | 107'749 | 194'375 |
| 6. Team Päiväniemi | 539 | 22'297 | 21'726 | 3'219 | 29'001 | 668 | 12'568 | 1'397 | 124'071 | 215'486 |
No changes in the top ranks. Team Heino didn't improve their performance but the lead was enough to keep to the first place, even though Team Kääriäinen did catch up a lot. The best improvement compared to Round 3 was made by Team Aunimo. Teams Heino and Kääriäinen will reveal the secret of their success at the Seminar.
Your task is to design, document, and implement a compressor and a decompressor program. All imaginable lossless compression methods are allowed. The compression rate of the program will be evaluated with a given set of data files. However, scoring will not be based solely on compression rate. Instead the size of the decompressor program is added to the size of the compressed files. Using too complex a decompressor program (e.g., a la style ''print "data...";'') will not generally be a good idea.
As a special feature, in some cases both the compressor and the decompressor programs have access to side information related to the file to be compressed. Using the side information is not obligatory, but it makes compression significantly easier, thus reducing the size of the compressed file.
Your documentation, due May 14, should describe
the ideas/observations/principles underlying the compressor and the
decompressor algorithms. A complete project is a tar-file (all links
should be relative and all files in the directory returned)
including
» high-level description (in English) of the algorithms,
» program source for both compressor and
decompressor programs.
The documentation can be delivered as a separate tar-file that can be extracted in the same directory as the programs.
In addition, two best groups will be giving a presentation about the basic ideas of your approach at the course seminar. Because the final results will be available only a short time before the seminar, all groups should be preliminarily prepared for giving a presentation.
In order to make the sizes of the programs comparable, programming language is Java for all groups (sorry about that). The programs must compile in Linux with the Makefile given in the project template. The usage of the programs must conform with the test script also found in the template. In particular, input is read from the standard input stream and a side information file specified on the command line (e.g., ''java mydecompress sideinfo.sdat <compressed.data >decompressed.data''). See the README file.
The form of the report is a WEB-page (the HTML template is included in the project template).
» Download the project template
If you run into problems, email questions to Teemu.
The performance of your algorithm will be evaluated with the given set of data files. The loss-function is given by:
where N is the number of data files,
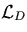 is the size of the decompressor program, and
is the size of the decompressor program, and
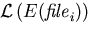 is the size of the compressed version of the ith file.
is the size of the compressed version of the ith file.
The competition is iterative, meaning that there are several deadlines. After each deadline your success is evaluated and scores are published. After each round you are also allowed to submit your own data which will be used in the competition on the remaining rounds. Each group is allowed a variable amount of data, the amount depending on your success on earlier rounds. Because you can probably compress your own data better than other groups it pays off to try to do well already on the first rounds. Project points will be based only on the final round scores though. Details of the data submission procedure are annouced later.
1. There is a bug in the mycompress and mydecompress scripts.
Yes, you're right. Instead of ''java -classpath cclass mycompress'' it should be ''java -classpath cclass mycompress $1''. And the same for mydecompress. I fixed the project template. (Thanks Jukka.)
2. Can the decompression program use other input than stdin and the side information file given on the command line?
No.
3. Can I use Java standard library java.___.___?
Yes.
4. Do I have use to Java standard library java.___.___? My class file gets too big.
No.
5. Making the class files small is a question of good/bad/ugly Java programming skills, not compression!
Unfortunately this is more or less the case. However, we expect the differences due to compression rate to be more significant than the differences due to programming style. If this turns out to be a problem, we will increase the sizes of the data files or think of something else. Besides, think of the bright side of things: We first thought of comparing the sizes of the source files! (See IOCCC.)
6. There is no point in using data from the other groups. They will be practically impossible to compress.
Yes, that's the idea. But don't worry, the submitted data files will be smaller than the ones given by us.
7. What are we supposed to do after the first round? Compressing other groups' data will be almost impossible, so there's no point in trying, and we will have done all the work by the first round.
That's the right attitude. Well, we didn't say that we won't add other data files ourselves.
8. Can the compressor and decompressor programs create and access temporary files in /tmp or elsewhere?
Yes.
9. Do the programs have to be general purpose applications, or does it suffice to be able to handle the given files?
Just the given files, with the given script (runtest.sh).
| 3 Concepts: Information | |